1.利用pandas把numpy数组保存为csv文件
接触pandas之后感觉它的很多功能似乎跟numpy有一定的重复,尤其是各种运算。不过,简单的了解之后发现在数据管理上pandas有着更为丰富的管理方式,其中一个很大的优点就是多出了对数据文件的管理。
如果想保存numpy中的数组元素到一个文件中,通过纯Python的文件写入当然是可以实现的,但是总觉得是少了一点便捷性。在这方面,pandas工具的使用就会让工作方便很多。下面通过一个简单的小例子来演示一下。
首先,创建numpy中的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
接着,为了能够使这组数据成为可以让pandas处理的数据,需要通过这个数组创建pandas的DataFrame。
这样,就可以通过pandas中DataFrame的to_csv方法实现数据文件的存储了。具体如下:
- 1
- 2
- 3
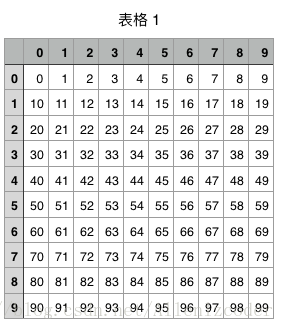
打开csv文件可以看出,转换成DataFrame的同时,数据信息增加了行列标题信息。
通过电子表格软件打开csv文件的效果如下:
大部分情况下,我们不需要行、列信息。则代码改为:
- 1
- 2
- 3
2.pandas.DataFrame.to_csv()中详细参数解释
DataFrame.to_csv(path_or_buf=None, sep=’, ‘, na_rep=”, float_format=None, columns=None, header=True, index=True, index_label=None, mode=’w’, encoding=None, compression=None, quoting=None, quotechar=’”’, line_terminator=’\n’, chunksize=None, tupleize_cols=False, date_format=None, doublequote=True, escapechar=None, decimal=’.’, **kwds)
Write DataFrame to a comma-separated values (csv) file
path_or_buf : string or file handle, default None
File path or object, if None is provided the result is returned as a string.
sep : character, default ‘,’
Field delimiter for the output file.
na_rep : string, default ‘’
Missing data representation
float_format : string, default None
Format string for floating point numbers
columns : sequence, optional
Columns to write
header : boolean or list of string, default True
Write out column names. If a list of string is given it is assumed to be aliases for the column names
index : boolean, default True
Write row names (index)
index_label : string or sequence, or False, default None
Column label for index column(s) if desired. If None is given, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex. If False do not print fields for index names. Use index_label=False for easier importing in R
nanRep : None
deprecated, use na_rep
mode : str
Python write mode, default ‘w’
encoding : string, optional
A string representing the encoding to use in the output file, defaults to ‘ascii’ on Python 2 and ‘utf-8’ on Python 3.
compression : string, optional
a string representing the compression to use in the output file, allowed values are ‘gzip’, ‘bz2’, ‘xz’, only used when the first argument is a filename
line_terminator : string, default ‘n’
The newline character or character sequence to use in the output file
quoting : optional constant from csv module
defaults to csv.QUOTE_MINIMAL
quotechar : string (length 1), default ‘”’
character used to quote fields
doublequote : boolean, default True
Control quoting of quotechar inside a field
escapechar : string (length 1), default None
character used to escape sep and quotechar when appropriate
chunksize : int or None
rows to write at a time
tupleize_cols : boolean, default False
write multi_index columns as a list of tuples (if True) or new (expanded format) if False)
date_format : string, default None
Format string for datetime objects
decimal: string, default ‘.’
Character recognized as decimal separator. E.g. use ‘,’ for European data
New in version 0.16.0.
pandas的数据,里面都有index,有列头,这个api里详细讲述了如何去掉index和列头
例子:
df.to_csv(‘/tmp/9.csv’,columns=[‘open’,’high’],index=False,header=False)
不要列头,不要索引,只要open,high两列。


发表评论 取消回复